GDBC: Azure learnings from running at scale
On the 15th of June we got the opportunity to organize the Global DevOps Bootcamp edition of 2019 (see link) and we had a blast!
![]()
For the 2018 edition we created challenges for the attendees to setup their CI/CD pipelines to push a web application into Azure. You can read up on the setup for that edition here.
Next level
Since we need to create something next level for each new edition we had a brainstorm session somewhere in November of 2018. How can we improve the experience for 2019?? We got quite some feedback that for the attendees that had no previous experience with Azure that some steps (e.g. creating a Service Principal) where to hard for them, both to understand and to execute. Although that story has improved a lot with for example the release of the Azure CLI, we wanted to make it even easier: what if we setup everything for the teams?
Team setup
So we would start them with a working web application, running in Azure including a database connection and application insights to boot. We also wanted to set them up with a complete Azure DevOps setup, so everything from a Git repository, CI/CD pipelines, working service connections, package management, the whole deal.
Find out more
If you want to know more about the whole setup, checkout the YouTube playlist the team has made around the event here. I helped creating the Azure DevOps scripts (together with René, Jasper and Sofie) and created the Azure setup myself. You can also look at this video explaining the Azure DevOps and Azure parts:
If you really want to find out more, I would love to come talk about all of it on conferences or meetups! You can find my session here. I am sending this session in for conferences, either alone or together with René.
Size
We decided to cap the venue count this year to a 100 venues. This would give us a limit in the amount of resources we needed to create and we could calculate an indication of the costs of those resources. We got 4 sponsored Azure subscriptions from Microsoft with limited budgets on them. From the tickets the venue organizers added in Eventbrite we could guess the scale we needed.
In the end we created:
- 1340 App Services,
- 96 SQL servers,
- 1340 SQL databases,
- 1340 Azure DevOps Teams in 7 Azure DevOps organizations (each with a full setup)
- 96 AAD Venue Team groups and users,
- 1340 AAD Team groups and users,
- 1340 AAD Team Service Principals
- 1340 team role assignments in 1340 + 96 resource groups
Learnings
Running at a scale like this means we where going to hit some weird stuff in the API’s we used. Here is what I learned by provisioning the Azure resources. There where some small things like the fact that not all resource providers are registered in new subscriptions. I knew that this was the case, but totally forgot about it. When I hit this issue, I was surprised that this even happens for the most ‘basic’ resource providers, like Application Insights and KeyVault! My colleague Pascal Naber has a blogpost about how to enable all the providers for a subscription. In our case I decided to not use that, and enable the providers we needed by hand in the four subscriptions we had. The main reason behind this was that we needed to make all the venue organizers and the team accounts Owner on the resource groups we would create for them, so they could actually do the things we wanted them to do. That would give them the rights to spin up everything they need, including the potentially more expensive things like ASE, DataBricks clusters or just VM’s. Just to be on the safe side I choose to leave those possibilities disabled.
Azure learning: Cloud resources are not always finite
I found out that Azure has limits on the amount of available resources you can create in each region. I already experienced that when I was attending Microsoft’s AI Bootcamp in January, when the proctors there indicated limited amounts of DataScience VM’s in each region. I figured this was a limitation based on the compute resources needed and the usual ‘standard’ resources would not have this limitation.
Imaging my surprise when I tested with creating SQL Servers in India:

Even switching to one of the other two regions in India didn’t help! Apparently some quota is set on Azure’s backend and you cannot create those resources 😲. Even testing a couple of weeks later still indicated it wasn’t possible! Eventually we moved those teams to Southeast Asia.
Azure learning: Portal search is not great
When you have a large Azure Subscription with a lot of resources in it, the search just is not that great. Searching for a wildcard in the beginning of a name isn’t possible, so searching for %brisbane% was not possible. That meant a lot of copy and pasting if I needed to find the teams resources to check them for something.
Azure learning: Azure SQL server limits
As I always want to segment users and teams from each other as much as possible, I wanted to create an Azure SQL Server per team at first. I knew there are soft limits and hard limits in Azure for some resource providers, like for example the amount of CPU cores you can allocate. There is a support process around it where you can ask to increase those quotas.
That reminded me to check the quotas for SQL Servers, Databases and App Service Plans that we needed to create. Luckily I did: there is a soft limit of 20 Azure SQL Servers per region in a subscription that can be increased with support tickets and a hard limit of 200 Azure SQL Servers per subscription! That would not work for the 1200+ teams that we had planned by the time I found out about this limit! We decided to switch to provision 1 SQL Server per venue (planning on max 100) and then create the database per team. That would mean that the teams could see and control the databases of ALL the teams in their venue, but we expected the teams to not screw up the databases of other teams. I also made sure the venue organizer would get a VenueAdmin account that could help out the teams in case of need. Since I wanted the attendees to be able to monitor their database for at least the Percentage DTU consumed, it meant that they needed to have those rights on the server, since you cannot set ACL’s on the database level. Note: we did create SQL Server User accounts for the databases as well, so we had different passwords per team.
Azure learning: Application Insights not available in all regions
Application Insights resource provider is not available in Central US! For me, Application Insights is a base provider that I’d use in any application I create or consult for. That made me expect that this provider would be available world wide, or at least at what I would consider standard or big regions. This is not the case! So the advise is: always check! We got tipped beforehand by an observant venue organizer in the last week before the event and we moved those web applications to East US.
Azure learning: 2000 role assignments per subscription
At first, I was making role assignments on a user level, based on the fact that I had that call working. There is a limit on how many assignments you can make per subscription! Read more about it in the docs.
If you get the error message "No more role assignments can be created (code: RoleAssignmentLimitExceeded)" when you try to assign a role, try to reduce the number of role assignments by assigning roles to groups instead. Azure supports up to 2000 role assignments per subscription.
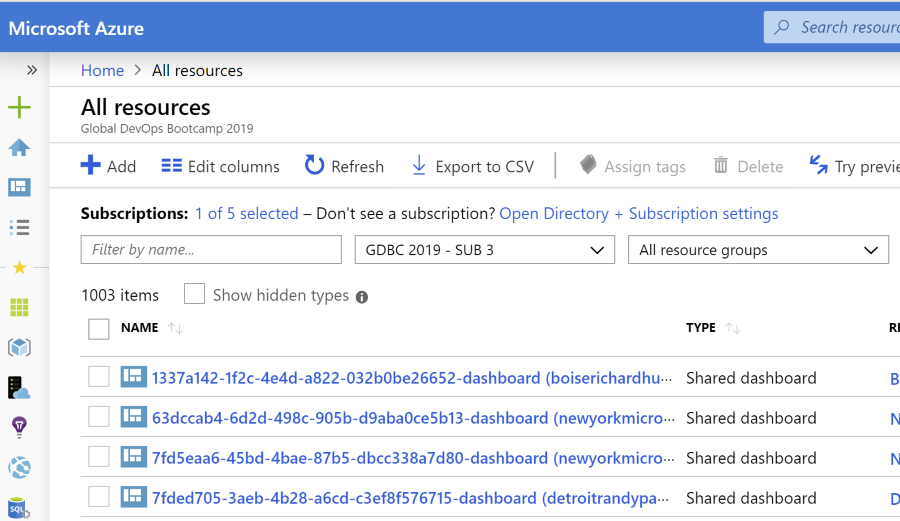
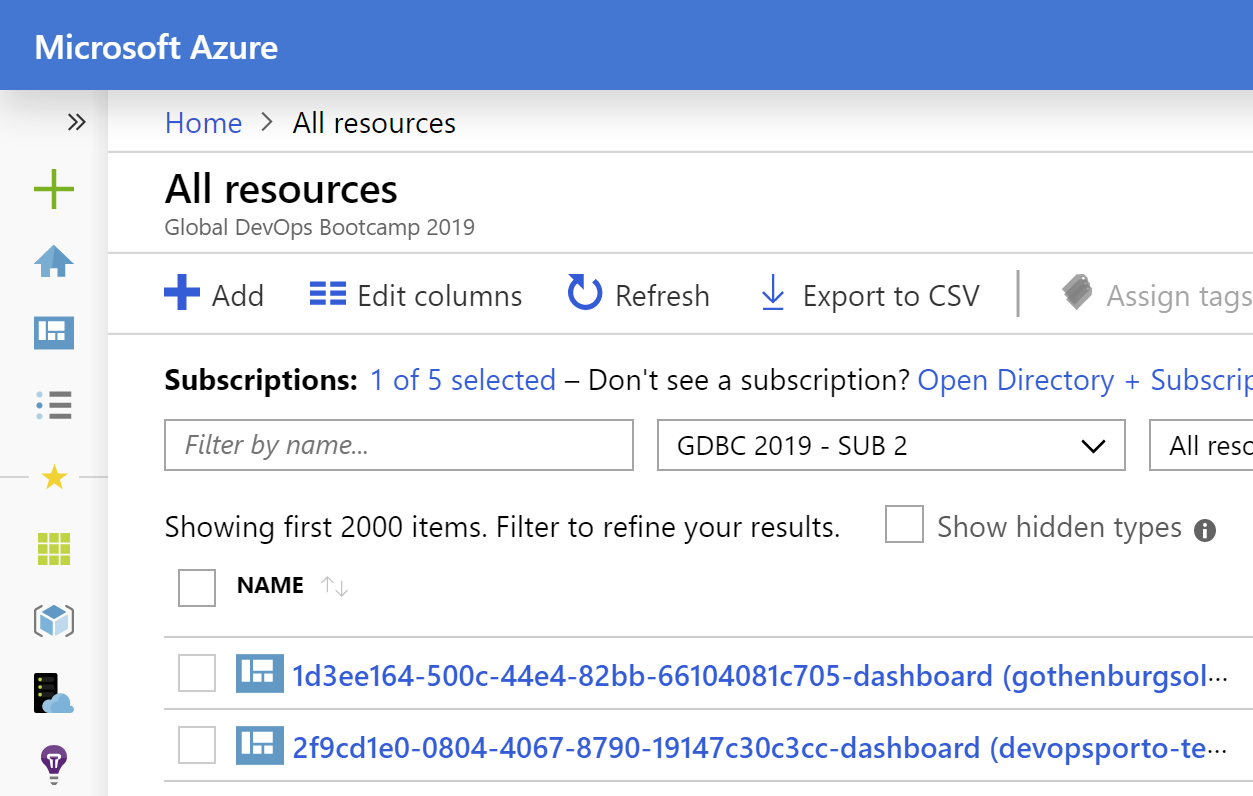
Azure learning: portal only shows the first 2000 resources in any pane
This only makes sense and is also present in the REST API, but the portal ‘only’ shows 2000 resources in the listings. This is at least the case in the All resources view.
Azure learning: always check the defaults or pick your own
This one was something I had not thought of for a long time: I was creating the Azure SQL databases with the default during testing. This meant that the teams got a S0 database which would cost us €0.0171/hour/database (remember that we needed 1350 databases!). Right in the period that we ran the full set of resources, the default changed!! Azure now picked a Gen 5 with 4 vCores that costed €0.9021/hour/hour/database! I ran through € 5.000 in less than a day, because of this!! 😱😱😱😱. Lucky that I found this, I ran an updated on all of them to resize them back to an S0. Also updated the code so I picked my own default and set that to an S0 as well.
You can find out more information about pricing here.
I could have also used a SQL Elastic Pool per venue and place the database in it, that would just have costed less euro’s and more time to build. I skipped it because I needed to do a lot of things in that last week 😉. You can read more about the last 48 hours of the event in another post.
Azure learning:
There are some calls that you can make that can fail in a weird way. I had several calls fail where I created both the Active Directory Application and the Service Principal to go along with it. Given that I made 1350 calls to this API and > 20 of them failed, this is quite interesting. Anyway: on failure: the Application would be created and the Service Principal would not! I quickly added a check on it that would just delete the Application so the next run would recreate it. Not sure if this is caused by the Fluent SDK that I was using.
servicePrincipal = await AzureClientsFactory.AADManagementClient.ServicePrincipals
.Define(spnName)
.WithNewApplication(spnName)
.DefinePasswordCredential("ServicePrincipalPassword")
.WithPasswordValue(spnPassword)
.Attach()
.CreateAsync().ConfigureAwait(true);
Azure DevOps learnings
I encountered the Azure DevOps REST API’s again and as in previous times, I am very grateful for all the experience and knowledge my colleagues René, Jasper and Jesse have with them! These API’s are documented but we seem to always need some exotic variant or a specific thing that is hard to find, for example setting default repository permissions on your Azure DevOps Organization, as documented by Jesse here. We knew that we needed to setup 1200+ team projects and the GDBC team has excellent contacts with the Azure DevOps product group, so we arranged 7 different Azure DevOps organizations. This would enable us to:
- spread the load on the service, we hit some weird quota’s and functionality issues last year,
- keep the latency low for the teams, since we could place them to an organization closest to them,
- run the CI/CD pipelines that would create the App Services and other resources as close as possible to the start of the event, so we could keep the costs low.
DOSsing the Azure DevOps service
Since we had 7 different organizations, René created a nice pipeline to start all the CI/CD pipelines after we created all the other setup (Git repo’s, Service connections, etc.).
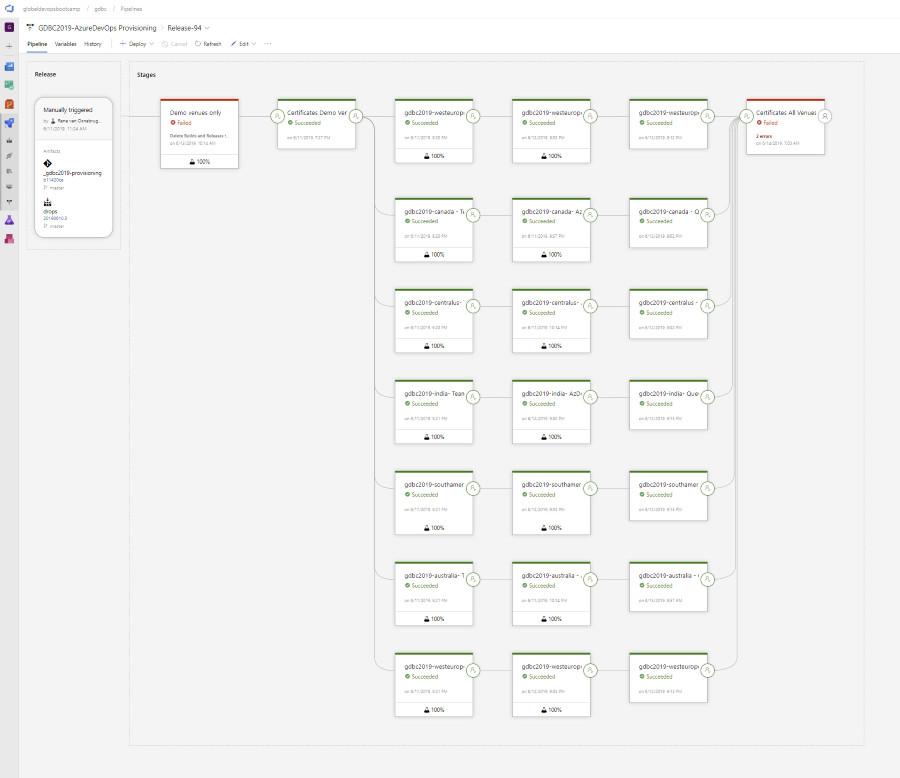
Getting the sponsoring from Microsoft also meant an increase in available Microsoft Hosted Pipelines. I learned later that you cannot even buy these numbers of pipelines as a regular customer! This meant that we either had 100 0r 160 hosted pipelines available (depending on the estimated size of the organization we would set up), so we could kick off all +/- 400 pipelines in each organization when needed.
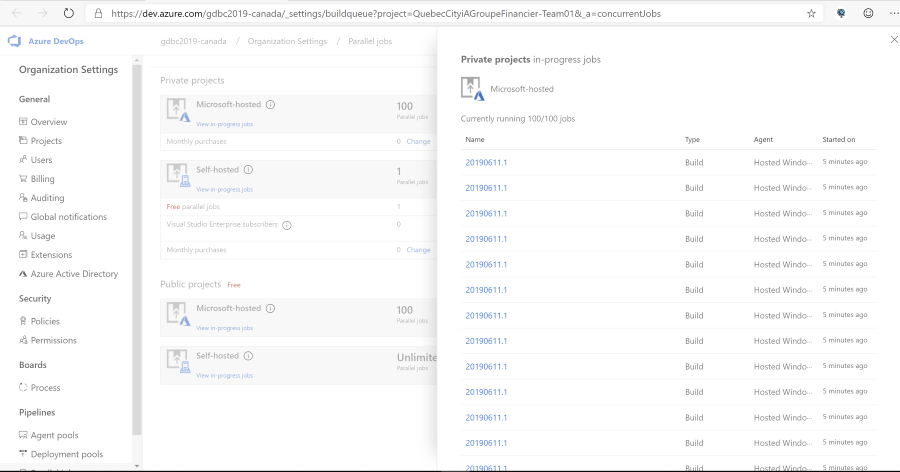
This would mean scheduling all 400 CI builds when we wanted, witch would all kick off their CD release on completion. This eventually meant rapid scaling of the pipelines in the region the Azure DevOps organization was linked to. Two off these regions had some serious issues handling that load!
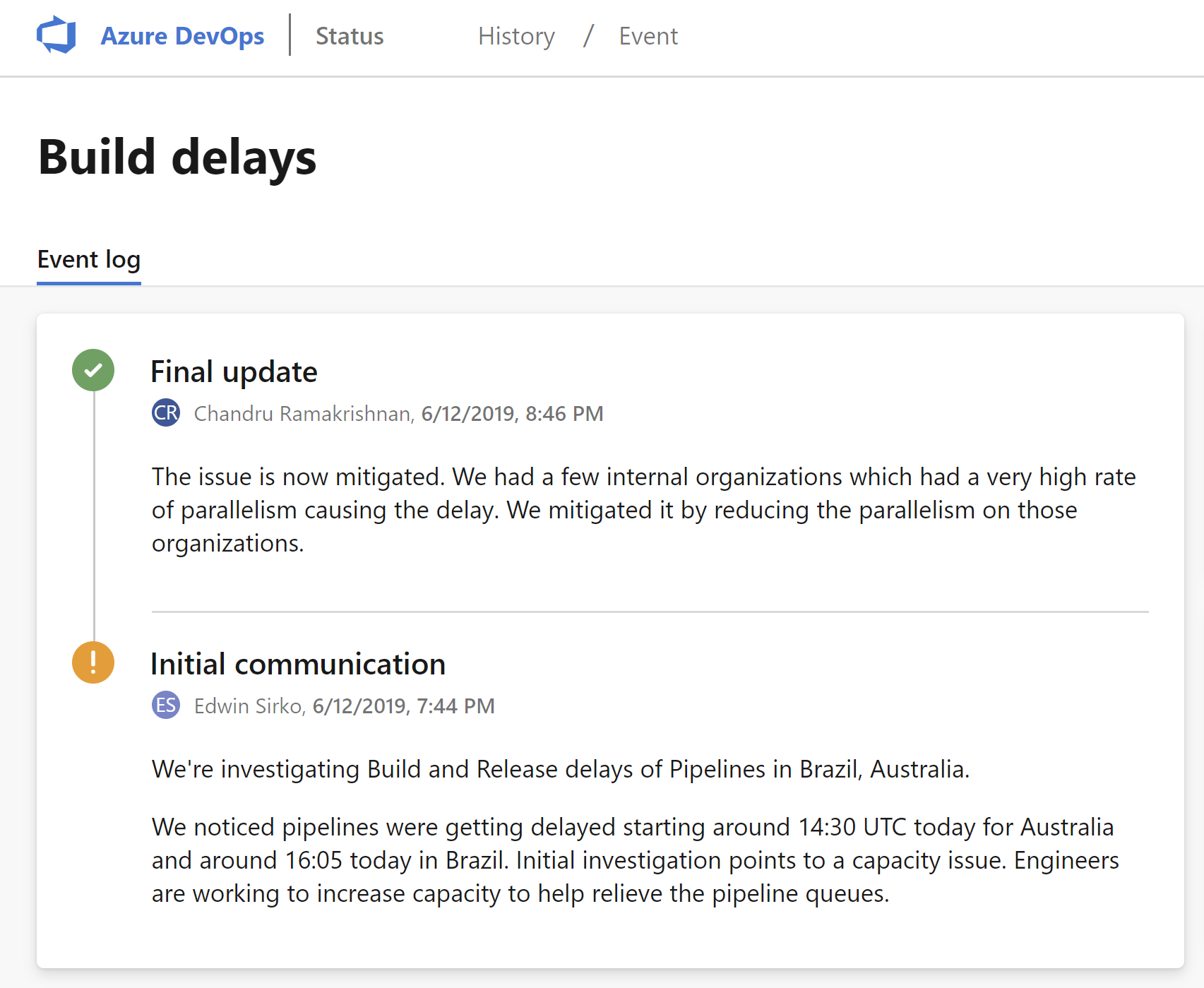
Eventually this was all sorted out by SRE’s in the Azure DevOps team, with great, direct support for us. I think the learned something about their own service in the end!
Azure DevOps functionality View in-progress jobs (bug)
Regarding the fly-out of the ‘View in-progress jobs’: there is a call to the backend to load all the running jobs. The fly-out will only show after that callback has completed. With a lot of team projects, this can take a long time to actually do the flying out. During that wait time, you can click the link multiple times: you will then get the fly-out multiple times and you can then close them one by one ![]() .
.
A refresh button on the fly-out would be nice as well, since this was one of the places I could check to see how the load on the organization was going and if we could start the next stage of our pipeline: right now you need to close the fly-out and then request it again ![]() .
.
Another small issue I have with this fly-out is that in more and more places, this fly-out can be closed by clicking on the area outside of it (for example in the build progress view). This fly-out hasn’t gotten this treatment yet.

