DevOps Maturity Levels - Continuous Deployment
If you have a good Continuous Integration process in place, you can start using the generated artefact to deploy that to an environment as the next state of enlightenment in your DevOps way of working. Check that link for posts on the other topics.
Note: in this case I specifically mention an environment: any place you can roll out your artefact is part of your Continuous Deployment strategy. Where specifically is part of forming your strategy and there are plentiful ways of doing so. Different strategies will be discussed further down in this post. For now, lets take rolling your application out onto a test environment as a starting point: the goal is to roll out the application so you can verify if things are working as expected. You typically do so on a test environment: something that is not production 😄.
Note: Application can be anything, but I’ll use a web-application as an example here
Note: Environment in this case will then be a hosting environment to run the application, so something of a webserver in this example
Note: I’ll use the application as running in the cloud as an example, some points can be made about other platforms
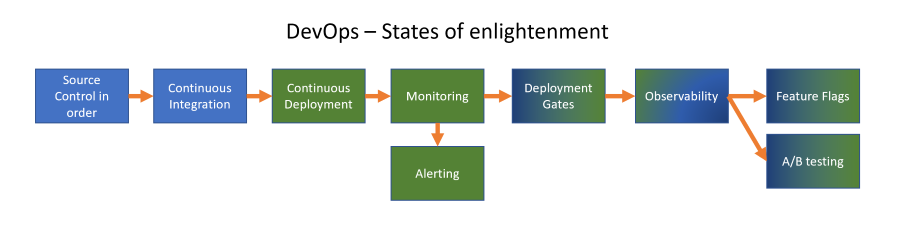
Continuous Deployment (CD)
There are some differentiation one can make about a difference between Continuous Delivery (deliver the artefact to a server) and Continuous Deployment (enabling the changes to an end-user). I’m not making that distinction in this post: the goal is to roll out a new version of the application to our test environment. As far as DevOps enlightenment goes I think the following steps can be separated out:
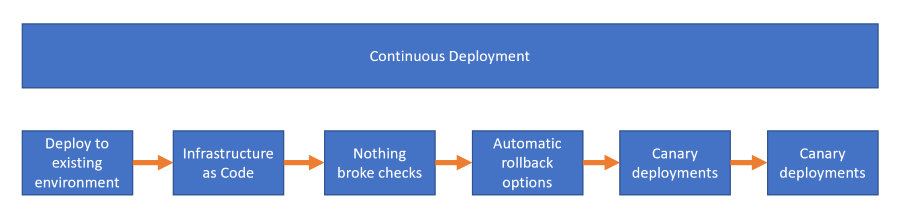
Deploy to an existing environment
When you start here, you’ll probably start with an existing environment. Perhaps you are already using a tool to deploy to that environment manually: time to step up your game and deliver the updates automatically. With DevOps tooling you can automate this process to deploy the update with each new artefact being created: you want to automatically trigger the start of your deployment when this happens and the CD pipeline should do the rest. In the cloud example you’d use these steps:
- Trigger the CD pipeline on a new artefact
- Download the artefact
- Connect to the hosting environment
- Deploy to the environment
- Signal the development team a deployment was successfully done
Infrastructure as Code (IaC)
A next step could be to start creating the environment you want to deploy to automatically as well. This enables you to:
- create a clean testing environment whenever you need, for example for a Pull Request verification build
- recover from issues with you environment for example when somebody accidentally deletes something
- rollout the environment in different cloud regions: when automating the creation of the environment this becomes very easy to do
This step does not necessarily come in this order and could be skipped in favor of the following two steps. You’ll probably find the need to start working with IaC soon thereafter, and adding it here usually saves you pain later on.
Nothing broke with the deployment checks
After rolling new version out automatically, it is good to add a step in the CD pipeline to verify that the application still is working as expected. You don’t want to rollout every change and find out from your users (or stakeholders!) that the test environment is not working! Better to add a step and verify yourself.
At first it could be a basic test: if I navigate to the web-application, do I get a HTTP 200 Ok response back:
url="https://devopsjournal.io"
status=`curl --silent --head $url | head -1 | cut -f 2 -d' '`
if [ "$status" != "200" ]
then
echo "status was other than '200': was '$status'"
exit 1
fi
This should at least tell you if your application can be loaded by the hosting environment and can load the start page. It doesn’t really tell you anything else.
A next step could be to add the additional tests you need to get more confidence in your application that indicate that it still is working as expected. You could go all out with this and start creating end-to-end tests for the application checking each and every screen and functionality. Unfortunately these tests are hard to build, maintain and slow to execute.
You can also add just the tests you need to verify that the basics are there: test the index page, maybe login with a test user and check if some mayor parts of the application can be loaded. Then you already have several end-to-end integration points you are testing as part of your deployment: the application itself, some user authentication and perhaps authorization and maybe even the way you build up your pages or a menu for example. Try to make sure you can run these test fast and in parallel to gain even more speed.
Automatic Rollback options
What do you want to happen when you detect that a new deployment fails? In DevOps we usually say we want to roll forward: find the issue, fix it and roll the new out to the environments. When starting to do Continuous Deployment, this is not always the first thing you think about. Perhaps rolling out doesn’t give you enough confidence yet. Or perhaps your rollout is not fast enough for this. And there is always the case where you want to investigate what is going wrong at all, before you can fix it. Finding the issue can take some time. In the meanwhile, you want to get back to a known state. This can be hard, depending on the way you rollout updates. For example, think of database upgrades here: if you are changing data in the update, perhaps the previous version of the application cannot handle the new database schema. There are ways to remediate that, giving you the opportunity to rollback: re-deploy the last known good version, enabling you to find the issue with the erroneous version.
Often, the systems you use for your CD pipeline has an option for rolling back to a previous version: this can either be triggered manually or automatically.
Canary deployments
Alright, when you have your setup so far that you can deploy to any environment, with confidence that the new version is still working and with a rollback option if needed, you can start thinking about Canary Deployments: a deployment to a subset of your users. This is a method to limit the scope of the changes to only a small part of your users in an effort to limit the possible issues that the new version has. This way you can monitor the changes and from that decide if the changes are behaving good enough to roll them out to a larger set of your users.
There are lots of ways to roll out to a subset of your users: you can use a percentage of the incoming requests and direct them to a new server and slowly ramp that up, or let the users set a setting that they want to be alpha/beta users (even for just one functionality). This enables you to monitor the environment and roll out with more confidence.
Deploy without downtime
Most deployments to a server involve some downtime. Overwriting files on a web server has issues with locks when files are in use. Some servers make your stop the running website, overwrite the files and then start serving incoming request again.
This stage goes well with the previous one: if you have the ability to get an environment and split the traffic up between the old and the new version, you have found the way to deploy without any downtime: the basis is that both the old and new version are running at the same time and you control where the request are going to.

